
Navigating Model Bloat in AI: The Challenge of Efficiency
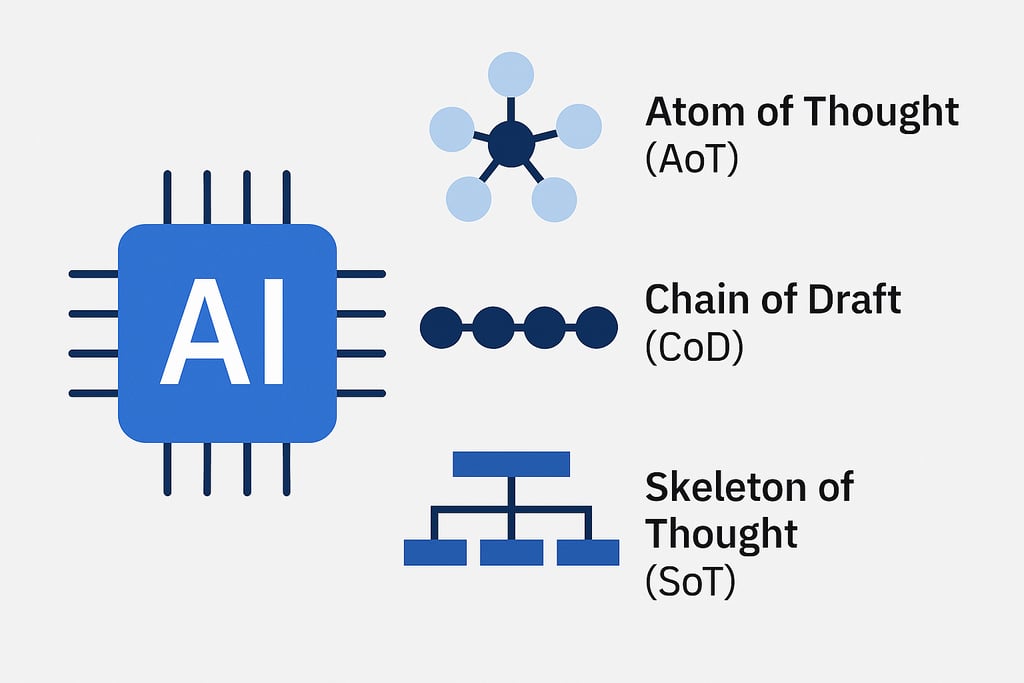
As AI models like OpenAI’s o1, DeepSeek-R1, and Google’s Gemini 2.5 push the boundaries of reasoning and intelligence, enterprises are becoming increasingly concerned about "model bloat"—the rising computational costs and slower response times of complex AI models. Innovative prompting techniques, such as Atom of Thought (AoT), Chain of Draft (CoD), and Skeleton of Thought (SoT), are emerging to combat this issue. These approaches enhance efficiency by optimizing how AI models reason, reducing latency and cutting costs while maintaining accuracy. 🔹 Atom of Thought (AoT): A divide-and-conquer strategy that processes problem steps in parallel, improving speed and efficiency. 🔹 Chain of Draft (CoD): Encourages AI to reason concisely, using fewer words and tokens while preserving accuracy. 🔹 Skeleton of Thought (SoT): Guides AI to draft structured responses first, then fills in details in parallel for faster processing. IBM's AI experts see these prompting strategies as game-changers for enterprises balancing AI performance with cost-effectiveness. As AI scientist Lance Elliott puts it, selecting the right prompting technique is like choosing the best tool for a job—it all depends on the task at hand.
ARTIFICIAL INTELLIGENCE
Niveeth Chattergy
4/3/20252 min read
Understanding Model Bloat
As advanced reasoning models such as OpenAI's O1, DeepSeek-R1, and Google's Gemini 2.5 rise to prominence in the realm of artificial intelligence (AI), one significant concern has surfaced: model bloat. This phenomenon refers to the trend of AI models becoming excessively large and complicated. Consequently, this escalation not only amplifies the computational costs but also elongates the model training time. For enterprises keen on integrating AI, understanding and mitigating model bloat is crucial for enhancing operational efficiency and maximizing return on investment.
The Role of Chain of Thought Reasoning
OpenAI's O1 and DeepSeek-R1 have adopted a remarkable approach known as Chain of Thought (COT) reasoning. This method enables models to decompose complex problems into manageable steps, yielding exceptional performance metrics and greater accuracy compared to earlier AI iterations. Nonetheless, the trade-off for achieving such proficiency is substantial. COT reasoning is resource-intensive, particularly during inference, which can lead to delayed response times. As enterprises move towards more powerful AI solutions, the intricacies of this computational demand warrant careful consideration.
Strategies to Mitigate Model Bloat
To combat model bloat, organizations can adopt various strategies aimed at optimizing their AI models. Firstly, implementing efficient architecture can significantly enhance performance while reducing resource demand. Techniques like model pruning, which eliminates unnecessary parameters, can also play a pivotal role in streamlining the models. Furthermore, quantization techniques reduce the precision of the calculations, thereby decreasing the memory and computation needs without sacrificing performance qualitatively.
Companies must also emphasize ongoing evaluation and iterative enhancements of their AI models. By leveraging feedback mechanisms and continuously monitoring the performance, organizations can identify what specific aspects contribute to bloat and adjust accordingly. This proactive approach not only bolsters efficiency but also enhances the executable performance of AI systems.
In conclusion, as enterprises navigate the complexities of integrating AI, addressing model bloat is imperative. With models like OpenAI’s O1 and DeepSeek-R1 leading the charge in AI capabilities through innovative reasoning methods, organizations must remain cognizant of the operational costs associated with these developments. Streamlining models not only facilitates cost-effective AI applications but also paves the way for faster and more accurate outcomes in real-world applications.
Insights
Expert consulting in AI and technology services.
Connect
Support
niveeth@nisonengineering.com
© 2025. All rights reserved.
Affiliate Disclaimer: Some of the links on this website are affiliate links, meaning I may earn a small commission if you make a purchase through them, at no extra cost to you. These commissions help support the content on this site and allow me to continue providing valuable information to my audience.Thank you for supporting this website!